Phonemic similarity exploration
Yesterday, I paired with Jacob on investigating Phoible, a really interesting structured dataset of phonemic inventories.
As a followup today, I set up a Jupyter notebook and deployed a report of it!
I also fixed an embarrassing bug (was previously using LanguageName as the unique identifier when that column wasn’t bijective with dialects), added a bunch of additional data explorations, and dug up a bit of background context on the languages that came up.
Observations
Basic stats
As of this post’s date, Phoible contains information on 3020 different dialects.
Here’s a histogram of phonemic inventory sizes, where the x-axis is the number of phonemes in the inventory and the y-axis denotes the number of dialects in that histogram bucket.
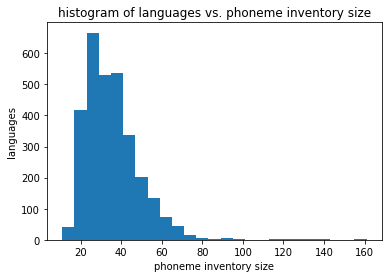
We see that inventory sizes of 20-45 phonemes comprise a significant bulk of tracked languages, although we have no particular guarantee that we are particularly familiar with those languages’ sounds.
Let’s ask the data some questions
Which langs have the largest and smallest phonemic inventories?
Largest: !Xóõ [161 phonemes], known for its very heavy use of click consonants.
Smallest: Pirahã [11 phonemes], an endangered language with under 1000 speakers.
Which pair of langs has the largest number of overlapping phonemes? (excluding pairs which are considered dialects of the same language)
Kanga (Kanga) [76 phonemes] and Kadugli (Miri) [63 phonemes], with 62 shared phonemes. Unsurprisingly, they are spoken very near each other, both in the Kordofan province of Sudan.
(Note that this metric is not equivalent to “largest percentage of overlap”, even though these two languages happen to have an extremely high degree of overlap.)
Do any pairs of langs have zero phonemic overlap?
Only 19 language pairs had no phonemic overlap whatsoever. Of these pairs, 11 contained Miyakoan (Ōgami dialect), spoken in the Miyako islands south of Okinawa, Japan.
This triggered a followup question…
Is Miyakoan a phonetically lonely language?
The answer: Not really. It shares a decent amount of phonemic overlap with several common languages.
Hakka Chinese (Kejia (Hakka Chinese, Meijiang, Meixian Hakka)) [47] sim=0.63
Eastern Hill Balochi (NA) [54] sim=0.58
Igbo (NA) [65] sim=0.53
Luo (NA) [35] sim=0.53
Yao (NA) [49] sim=0.47
Thai (NA) [45] sim=0.47
Swahili (NA) [36] sim=0.47
Zulu (NA) [43] sim=0.47
Norwegian (NA) [48] sim=0.47
English (NA) [40] sim=0.47
Which pair of languages has the largest phonemic union?
(The idea here being: what pair of languages might you teach a child to give them the maximum native phonemic inventory?)
274 phonemes, from the union of !Xóõ [161 phonemes] and Kildin Saami [128 phonemes], an endangered language spoken in Russia by less than 1000 speakers.
American English
I next attempted to ask the question, “What languages have high phonemic overlap with English?” on the assumption that this would make them easier for me to learn as an English speaker.
As a side note, the dataset only contained Western/Midwestern and Southeast Michigan variants. (Unfortunately for representation, I didn’t see Black American vernacular or any other common dialects of American English.)
Other than the obvious similarities with other English dialects in the dataset (ranging from an overlap of 69%-87% of their phonemes), the languages with the highest percentage overlap were:
- Persian, a Western Iranian language, which contains a uvular stop, something English speakers often have trouble with.
- Kwangali, which was unexpected to me as it contains multiple click consonants (though nowhere near as many as ǃXóõ), which English speakers struggle with even more than stops.
I quickly checked the overlap between American English and Japanese because I personally found Japanese phonemes really straightforward to pick up and I’ve been telling people they have a lot of phonemic overlap. I was totally quantitatively incorrect on that; they only overlap by 15 phonemes. However, the types of non-overlapping phonemes found in Japanese are significantly less unusual to English-speaking ears than clicks and stops.
In other words, phoneme inventory intersections are pretty far off from applied/perceptual phonetic differences between languages.
Hypothesis: Perceptual phonemic similarity between languages is difficult to gauge without additional usage information (phonotactics, frequency weighting, etc)
The simple aggregates and set operations above don’t appear to tell much of the story if used to evaluate linguistic similarity. They don’t line up at all with my human intuitions for linguistic similarity, even phonetically (putting aside grammar and phonotactics).
David J. Peterson states that if a language contains a phoneme which is rare amongst languages, it will frequently maximize listener comprehension by using that phoneme quite a lot, possibly even making that phoneme (or class of phonemes) a defining characteristic of the spoken language. Examples include:
- American English’s rhotic r (
[r], “red”) - Hindi’s retroflex t (
[ʈ], टापू [ʈaːpuˑ]) - ǃXóõ’s heavy use of click consonants
Even if a language shares an extremely large set of phonemes with American English, it may seem inaccessible if its most characteristic sounds are ones that Americans have little to no concept of, such as clicks or stops.
So, given a dataset of phonemes weighted by frequency of use in the language, we might be able to better calculate an intuition-aligned dis/similarity index.
We also don’t have a dataset for phonotactics – the complex rules that govern how phonemes are strung together. As one example of when this might obfuscate perceptual dis/similarity, “ng” [ŋ] is incredibly common in American English at the ends of syllables (“thing”, “running”, etc.), but is never used to begin a syllable, so Americans often perceive syllable-onset [ŋ] (which is super common in Southeast Asian languages) as weird.
Closing remarks
In terms of code, I just used vanilla Python out of habit & familiarity; pandas might be a better fit for querying next time.
Despite my strong enthusiasm for linguistics, I’m pretty novice at it, so please feel free to send me corrections if I said anything inaccurate!
Although the original questions I had weren’t a great fit for the data and didn’t do it justice, this is a wonderfully structured dataset and I’m excited to use it more in the future.
While veering off course, I was exposed to the existence of many endangered languages, and learned a lot about how vast the differences in phonemic inventories can be across languages. This was an interesting exploration!