oddly specific little puzzle tools
I made a web home for some puzzle tools I had lying around on my laptop! They are all oddly specific tools I have written for specific use cases, so we’re not talking anything powerfully generalized here. Just for fun!
scrabble scorer for many languages (sunday 7/28)
While working on T (Counts) For Two on MIT Mystery Hunt 2024 this year, we quickly realized it was a huge pain in the butt to hand-evaluate Scrabble scores in other languages we didn’t know.
I slammed out a Python script on the fly to eat Wikipedia descriptions of international Scrabble rubrics, and score multi-character token strings with diacritics. Then I shared the script, but then just ended up running it on my machine for my teammates’ input anyways…
Even though I will never need to use this exact thing again for Hunt – because even if a future international Scrabble puzzle appears, it will one-up this one in some elaborately exponential way such that a previous solution will not work – I ported it to web just for fun. Pchnąć w tę łódź jeża lub ośm skrzyń fig.
For the sake of future-proofing, I spent a little bit of the next day experimenting with a Pyodide implementation to see if slapping in the original Python script would perform alright. Even though I had already implemented this tool in JS, I always write in Python for efficacy when I’m slamming something out as fast as possible in the middle of Hunt, so I thought it would be nice for future scripts.
Sadly, I did not like the perceptible load time, so I threw away the Pyodide implementation and left up the JS version.
multi-character tokenizer (monday 7/29)
For tokenizing utterly wretched puzzlehunt ciphers like the first 1-26 pokemon of each of 8 pokemon generations, less-wretched non-Roman character sets, and more. I find myself rewriting one of these just about every Hunt.
It’s very fast to write, but when you’re in the middle of Hunt doing arcane 4-way spreadsheet witchery at top speed with both in-person and remote solvers simultaneously, there can be a sense of urgency and it’s also less blocking if everyone else can easily use the script too. So I thought it would be nice to make a web tool with a substitution feature.
To actually be useful for Hunt, it would be better if I added the ability to upload giant text files.
wordle solver (friday 8/02)
Next, I made a web interface where you can input your Wordle constraints and it outputs all the matching words in the Wordnik dictionary. You can set it to arbitrary word lengths too.
Why? While I don’t do much Wordle, the interface & regex generator for this seemed like a logical subproblem of making…
IPA wordle solver (saturday 8/03)
I’ve been doing a lot of daily phonetic Wordle recently and it’s been fantastic for solidifying my IPA (International Phonetic Alphabet) recall. Technically, these are built in GAE (“General” American English), so they’re only using a subset of IPA.
- Heardle: vanilla IPA wordle with dictionary validation
- Gramle: IPA wordle with less guesses and no dictionary validation, but you get to see a spectrogram of someone pronouncing the word.
While I think it’s pointless to cheat at these games by default (the point is to build the connections in your brain), phonetic Wordle is VERY weird, so sometimes I get stuck and am sitting there for half an hour desperately sounding out nonsense words and trying to figure out what word I could possibly enter next. At this point I need to get on with my day and I want just a little hint to help me take the next step.

An unusually perplexing daily Heardle; I have never gone more than 1 guess without hitting a single phoneme before. Do you have any idea how hard it is just to think of American English words that *don't* use any schwas???
Since most people don’t have an IPA keyboard installed, I started by making a simple GAE IPA keyboard interface.
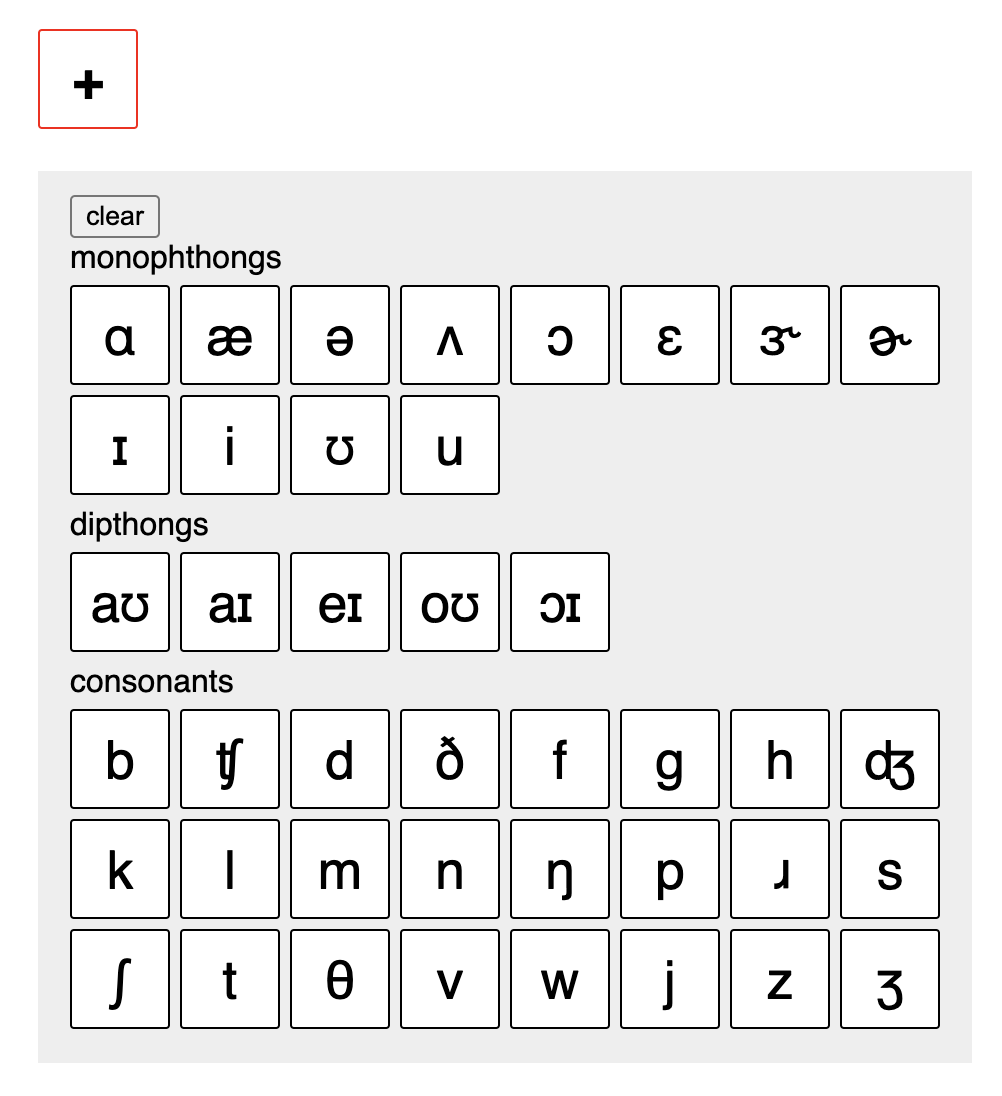
data source
cmudict, or CMU Pronouncing Dictionary, is the standard data source for pronunciation of General American English.
A bit of command line slicing and dicing reveals:
- 134303 total entries
- 133457 unique spellings
- 115377 unique pronunciations
In other words, both homophones and homonyms are present in cmudict, meaning you cannot assume a bijective mapping between English spelling and pronunciation. Since my search is phonetic by nature, I stored a mapping from pronunciations to lists of possible spellings.
data representation
cmudict encodes phonemes in a modified version of ARPABET; for example, /pɹənaʊns/ (“pronounce”) would be encoded as P R AH0 N AW1 N S.
I use IPA for all user-facing phonetic representations because it’s designed for human reading and it’s just what people are more familiar with. Under the hood, I’m translating from cmudict ARPABET.
ARPABET works well as an intermediate data representation because it’s designed more for computer use than human reading. Since it uses only roman alphanumeric characters (…and computers are extremely Western-centric), it’s very portable, unlike IPA characters which are not guaranteed to copy and paste into just any text environment out there.
ARPABET unfortunately does not seem to draw an unambiguous distinction between ɝ and ɚ, although I could probably infer/approximate various cases from the stress annotation system.
word search & regex lookahead
A reminder about how Wordle character constraints work:
- grey: not allowed anywhere
- green: match in a known position
- yellow: not found at a certain position, but must be included somewhere in the word
So a single regex pass can satisfy Wordle green & grey constraints, and the negative yellow constraint, but not the positive yellow constraint. (At each position, we can match either the green if one exists, or say “NOT any of the greys, and NOT any yellows attached to this position”.)
A standard regex “consumes” a string it successfully matches. Regex lookahead matches without consuming the string. In other words, you match a pattern, and then the next expression starts looking from the same start position as the lookahead did. So I used lookahead to match all yellow positive requirements, and then stuffed the grey, green, and yellow-negative requirements into the final expression.
I have never used regex lookahead before this! I’ve just surprisingly never been in a situation that demanded it so clearly before, even in industry. I’ve been missing out! (There’s also lookbehind, but I didn’t need to use it for this.)
How do regex engines work and why on earth are they so blazing fast?? While finite automata are conceptually straightforward, I feel like regex speed in practice still totally breaks my intuition, and I do not know how precisely they are implemented under the hood that makes them so fast. I mean, I am matching book-length strings against total monstrosities like this:
/(?=,T [\w ]+,|,[\w ]+ T,|,[\w ]+ T [\w ]+,)(?=,R [\w ]+,|,[\w ]+ R,|,[\w ]+ R [\w ]+,),P (?!R)(?!AH)(?!AH0)\w+ (?!AH)(?!AH0)\w+ (?!AH)(?!AH0)\w+ (?!AH)(?!AH0)\w+,/g
Alas, it will have to be an exploration for another time, as it is getting late and I have no idea.
filtering for word quality
cmudict is riddled with proper nouns and other non-dictionary words, which is not what I want in a word search.
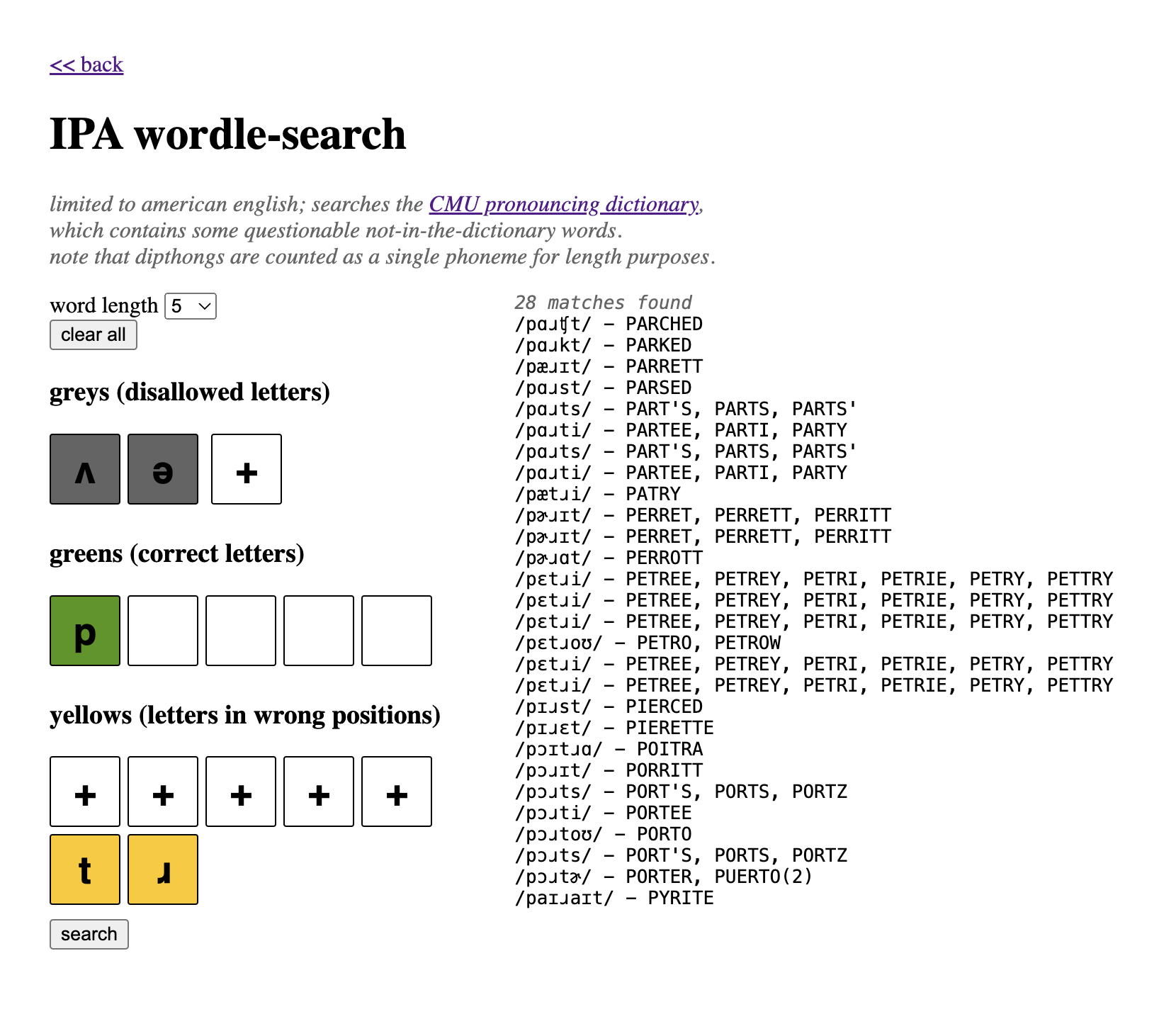
I filtered my data to only include words whose spellings were included in Wordnik, which I already had lying around from building the normal Wordle solver. This yielded much higher quality results.
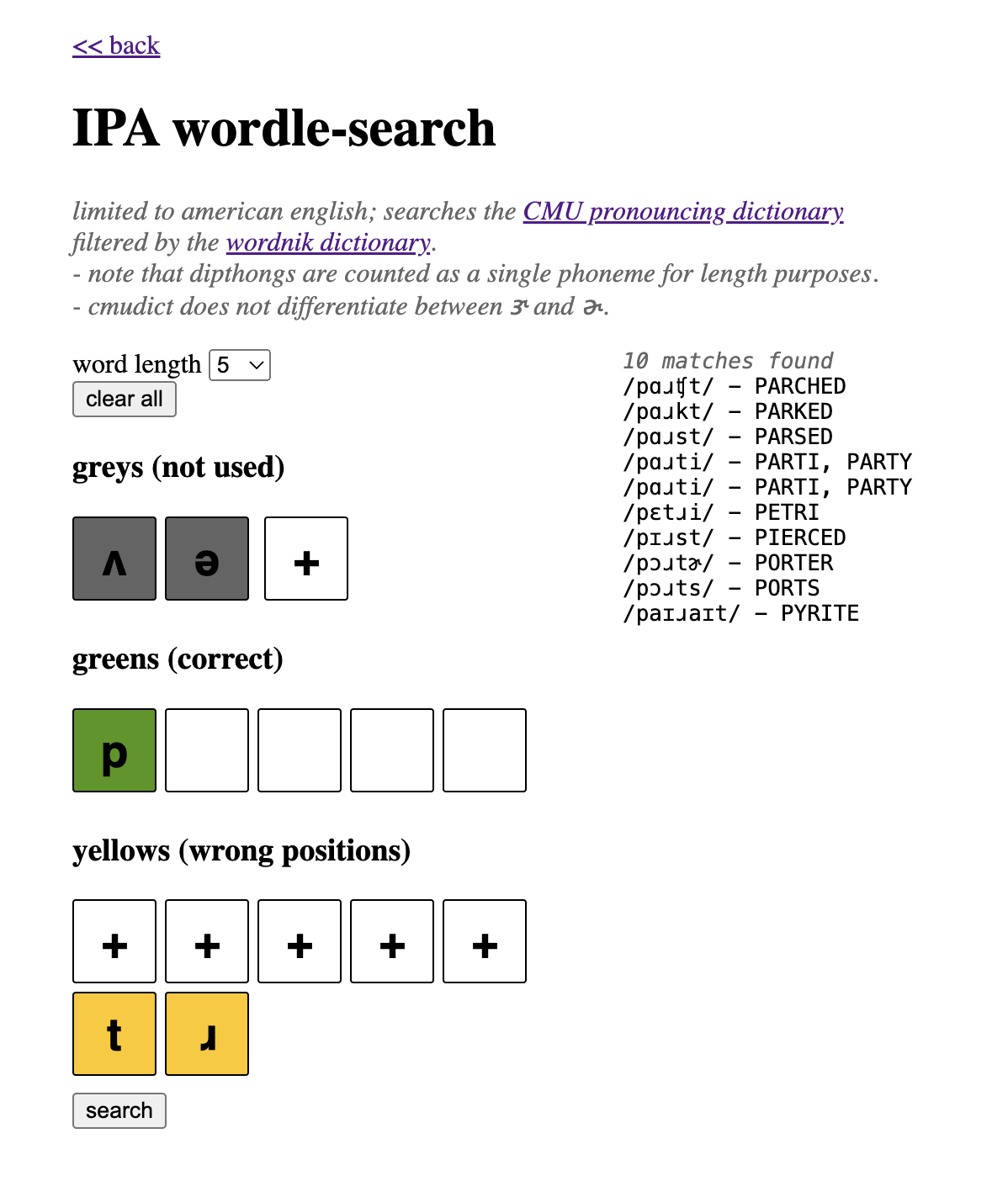
As a bonus, filtering by Wordnik cut down my preprocessed data’s filesize by 60%, or 4Mb!